AWS Big Data Blog

Migrate Amazon Redshift from DC2 to RA3 to accommodate increasing data volumes and analytics demands
As businesses strive to make informed decisions, the amount of data being generated and required for analysis is growing exponentially. This trend is no exception for Dafiti, an ecommerce company that recognizes the importance of using data to drive strategic decision-making processes. With the ever-increasing volume of data available, Dafiti faces the challenge of effectively managing and extracting valuable insights from this vast pool of information to gain a competitive edge and make data-driven decisions that align with company business objectives. The growing need for storage space to maintain data from over 90 sources and the functionality available on the new Amazon Redshift node types, including managed storage, data sharing, and zero-ETL integrations, led us to migrate from DC2 to RA3 nodes. In this post, we share how we handled the migration process and provide further impressions of our experience.
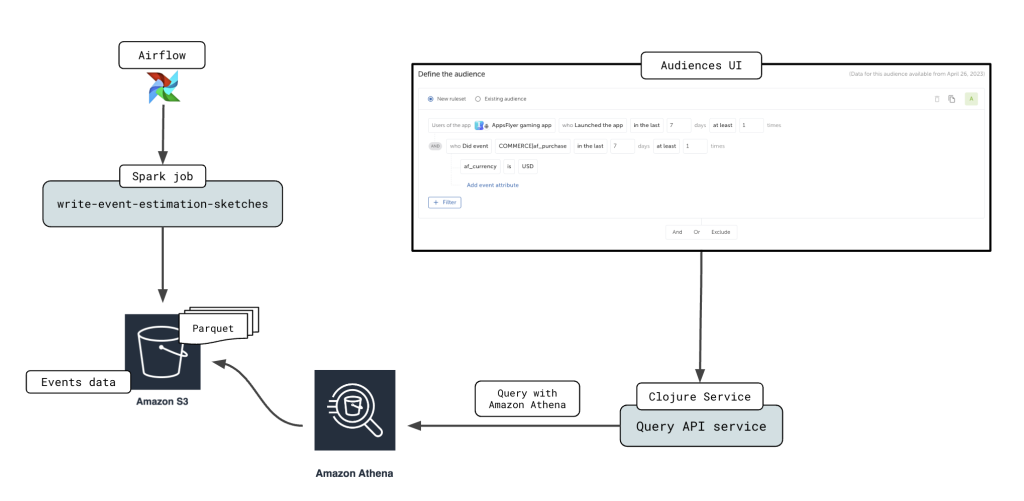
How AppsFlyer modernized their interactive workload by moving to Amazon Athena and saved 80% of costs
AppsFlyer develops a leading measurement solution focused on privacy, which enables marketers to gauge the effectiveness of their marketing activities and integrates them with the broader marketing world, managing a vast volume of 100 billion events every day. This post explores how AppsFlyer modernized their Audiences Segmentation product by using Amazon Athena.

Stream data to Amazon S3 for real-time analytics using the Oracle GoldenGate S3 handler
Modern business applications rely on timely and accurate data with increasing demand for real-time analytics. There is a growing need for efficient and scalable data storage solutions. Data at times is stored in different datasets and needs to be consolidated before meaningful and complete insights can be drawn from the datasets. This is where replication […]

Query AWS Glue Data Catalog views using Amazon Athena and Amazon Redshift
Glue Data Catalog views is a new feature of the AWS Glue Data Catalog that customers can use to create a common view schema and single metadata container that can hold view-definitions in different dialects that can be used across engines such as Amazon Redshift and Amazon Athena. In this blog post, we will show how you can define and query a Data Catalog view on top of open source table formats such as Iceberg across Athena and Amazon Redshift. We will also show you the configurations needed to restrict access to the underlying database and tables. To follow along, we have provided an AWS CloudFormation template.

Introducing AWS Glue Data Quality anomaly detection
We are excited to announce the general availability of anomaly detection capabilities in AWS Glue Data Quality. In this post, we demonstrate how this feature works with an example. We provide an AWS Cloud Formation template to deploy this setup and experiment with this feature.

OpenSearch optimized instance (OR1) is game changing for indexing performance and cost
Amazon OpenSearch Service securely unlocks real-time search, monitoring, and analysis of business and operational data for use cases like application monitoring, log analytics, observability, and website search. In this post, we examine the OR1 instance type, an OpenSearch optimized instance introduced on November 29, 2023. OR1 is an instance type for Amazon OpenSearch Service that […]
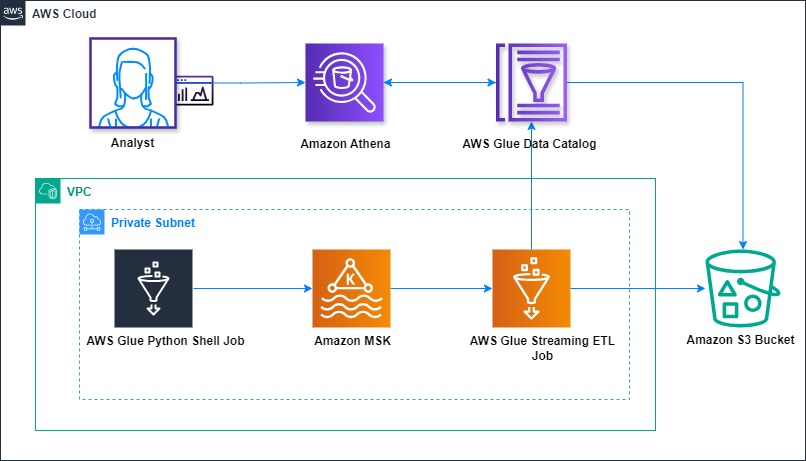
AWS Glue mutual TLS authentication for Amazon MSK
In today’s landscape, data streams continuously from countless sources such as social media interactions to Internet of Things (IoT) device readings. This torrent of real-time information presents both a challenge and an opportunity for businesses. To harness the power of this data effectively, organizations need robust systems for ingesting, processing, and analyzing streaming data at […]

Enrich, standardize, and translate streaming data in Amazon Redshift with generative AI
Amazon Redshift ML is a feature of Amazon Redshift that enables you to build, train, and deploy machine learning (ML) models directly within the Redshift environment. Now, you can use pretrained publicly available large language models (LLMs) in Amazon SageMaker JumpStart as part of Redshift ML, allowing you to bring the power of LLMs to analytics. You can use pretrained publicly available LLMs from leading providers such as Meta, AI21 Labs, LightOn, Hugging Face, Amazon Alexa, and Cohere as part of your Redshift ML workflows. By integrating with LLMs, Redshift ML can support a wide variety of natural language processing (NLP) use cases on your analytical data, such as text summarization, sentiment analysis, named entity recognition, text generation, language translation, data standardization, data enrichment, and more. Through this feature, the power of generative artificial intelligence (AI) and LLMs is made available to you as simple SQL functions that you can apply on your datasets. The integration is designed to be simple to use and flexible to configure, allowing you to take advantage of the capabilities of advanced ML models within your Redshift data warehouse environment.

How Amazon GTTS runs large-scale ETL jobs on AWS using Amazon MWAA
The Amazon Global Transportation Technology Services (GTTS) team owns a set of products called INSITE (Insights Into Transportation Everywhere). These products are user-facing applications that solve specific business problems across different transportation domains: network topology management, capacity management, and network monitoring. As of this writing, GTTS serves around 10,000 customers globally on a monthly basis, […]

Build a real-time analytics solution with Apache Pinot on AWS
In this, we will provide a step-by-step guide showing you how you can build a real-time OLAP datastore on Amazon Web Services (AWS) using Apache Pinot on Amazon Elastic Compute Cloud (Amazon EC2) and do near real-time visualization using Tableau. You can use Apache Pinot for batch processing use cases as well but, in this post, we will focus on a near real-time analytics use case.