
One of the lessons of the machine learning revolution has been that, perhaps counterintuitively, training a model on multiple data types or multiple tasks can improve performance relative to single-purpose models. A model trained on multiple languages, for instance, can learn distinctions that are subtle in one language but pronounced in another, and a model trained on, say, object segmentation may learn properties of visual scenes that help it with depth perception.

The advantages of multitask and multimodal training, however, are relatively unexplored in the context of diffusion models, which are responsible for some of the most impressive recent results in generative AI. Diffusion models are trained to incrementally denoise samples to which noise has been incrementally added. The result is that feeding them random noisy inputs will yield randomized outputs that are semantically coherent.
In a paper we presented at the International Conference on Learning Representations (ICLR), we describe a general approach to building multimodal, multitask diffusion models. On the input side, we use modality-specific encoders to map data to a shared diffusion space; on the output side, we use multiple task-specific decoders to map general representations to specific outputs.

The paper presents a theoretical analysis of the problem of generalizing diffusion models to the multimodal, multitask setting, and on the basis of that analysis, it proposes several modifications of the loss function typically used for diffusion modeling. In experiments, we tested our approach on four different multimodal or multitask data sets, and across the board, it was able to match or improve performance relative to single-purpose models.
Minding modality
In the standard diffusion modeling scenario, the model’s encoder maps inputs to a representational space; within that space, a forward process iteratively adds noise to the input representation, and a reverse process iteratively removes it.

The loss function includes two terms that measure the distance between the probability distribution of the forward process and the learned probability distribution of the reverse process. One term compares the marginal distributions for the two processes in the forward direction: that is, it compares the likelihoods that any given noisy representation will occur during the forward process. The other term compares the posterior representations of the reverse process — that is, the likelihood that a given representation at time t-1 preceded the representation at time t. We modify these terms so that the distributions are conditioned on the modality of the data — that is, the distributions can differ for data of different modalities.
Both of these loss terms operate in the representational space: they consider the likelihood of a particular representation given another representation. But we also have a term in the loss function that looks at the probability that an input of a given modality led to a particular representation. This helps ensure that the reverse process will correctly recover the modality of the data.
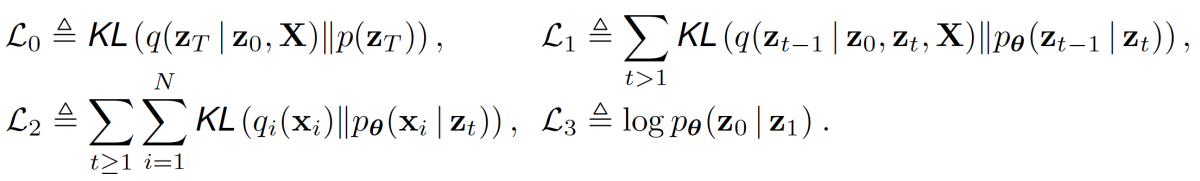
Multimodal means
To fuse the multimodal information used to train the model, we consider the transition distribution in the forward direction, which determines how much noise to add to a given data representation. To compute the mean of that distribution, we define a weighted average of the multimodal input encodings, where the weights are based on input modality.
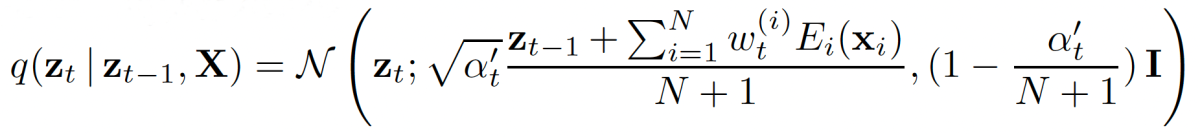
On the basis of the transition probabilities of the forward process, we can now compute the marginal distributions of noisy representations and the posterior distributions of the reverse process (corresponding to sublosses L0 and L1 in the loss function):
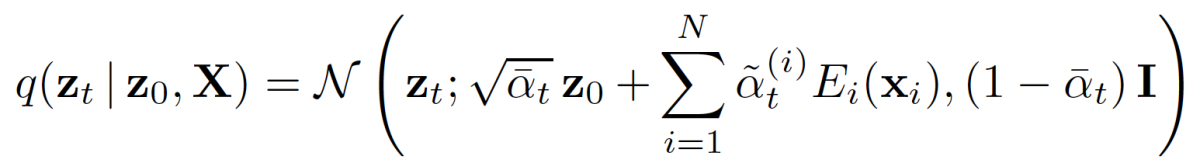
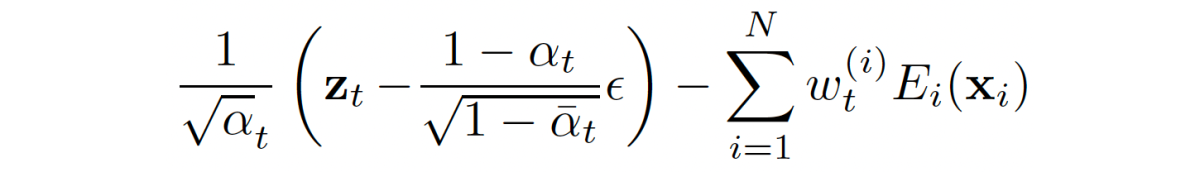
Evaluation
We tested our approach on four tasks, two of which were multitask, and two of which were multimodal. The multitask experiments were both in the vision domain: one involved jointly generating visual data and the associated segmentation masks, and the other was a novel multitask pretraining task in which a diffusion generation model also learned fill in masked regions of input images.

The multimodal experiments involved images and other modalities. In one, the model was trained to jointly generate images and their labels, and in the other, the model learned to jointly generate images and their embeddings in a representational space — for instance, CLIP embeddings.
The image segmentation was and embedding generation tasks were chiefly intended as qualitative demonstrations. But the masked pretraining task and the joint generation of images and labels allowed for quantitative evaluation.

We evaluated the masked pretraining model on the task of reconstructing the masked image regions, using learned perceptual image patch similarity (LPIPS) as a metric. LPIPS measures the similarity between two images according to their activations of selected neurons within an image recognition model. Our approach dramatically outperformed the baselines, which were trained only on the reconstruction task, not (simultaneously) on the diffusion task. In some cases, our model’s error rate was almost an order of magnitude lower than the baseline models’.

On the task of jointly generating images and labels, our model’s performance was comparable to that of the best baseline vision-language model, with slightly higher precision and slightly lower recall.
For these initial experiments, we evaluated multitask and multimodal performance separately, and each experiment involved only two modalities or tasks. But at least prospectively, the power of our model lies in its generalizability, and in ongoing work, we are evaluating on more than two modalities or tasks at a time and on simultaneous multimodal and multitask training. We are eager to see the result.



