Automatic speech recognition (ASR) models, which convert speech into text, come in two varieties, causal and noncausal. A causal model processes speech as it comes in; to determine the correct interpretation of the current frame (discrete chunk) of audio, it can use only the frames that preceded it. A noncausal model waits until an utterance is complete; in interpreting the current frame, it can use both the frames that preceded it and those that follow it.
Causal models tend to have lower latencies, since they don’t have to wait for frames to come in, but noncausal models tend to be more accurate, because they have additional contextual information. Many ASR models try to strike a balance between the two approaches by using lookahead: they let a few additional frames come in before deciding on the interpretation of the current frame. Sometimes, however, those additional frames don’t include the crucial bit of information that could resolve a question of interpretation, and sometimes, the model would have been just as accurate without them.
In a paper we presented at this year’s International Conference on Machine Learning (ICML), we describe an ASR model that dynamically determines lookahead for each frame, based on the input.
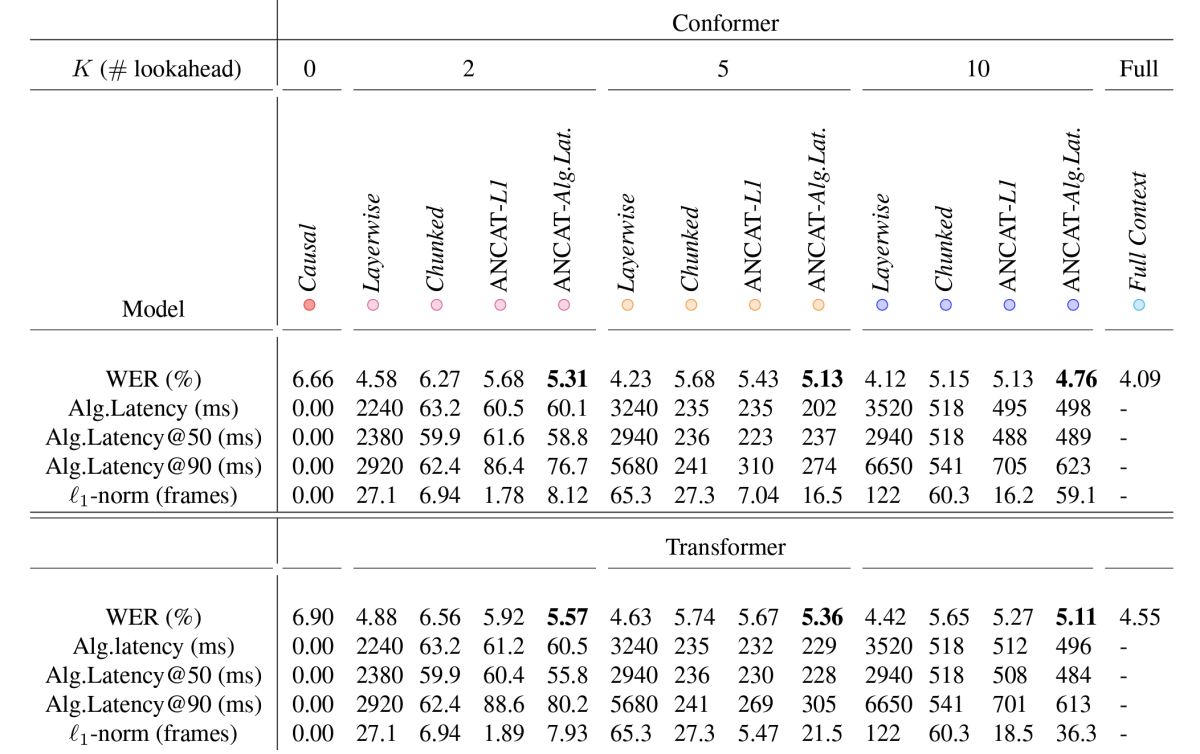
We compared our model to a causal model and two standard types of lookahead models and found that, across the board, our model achieved lower error rates than any of the baselines. At the same time, for a given error rate, it achieved lower latencies than either of the earlier lookahead models.
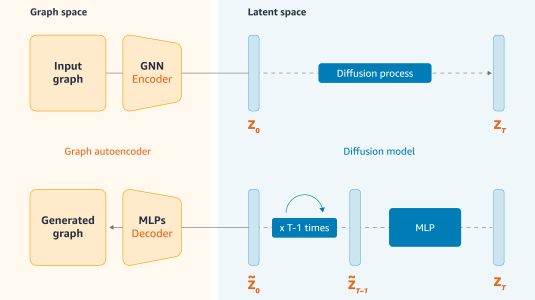
Computational graph
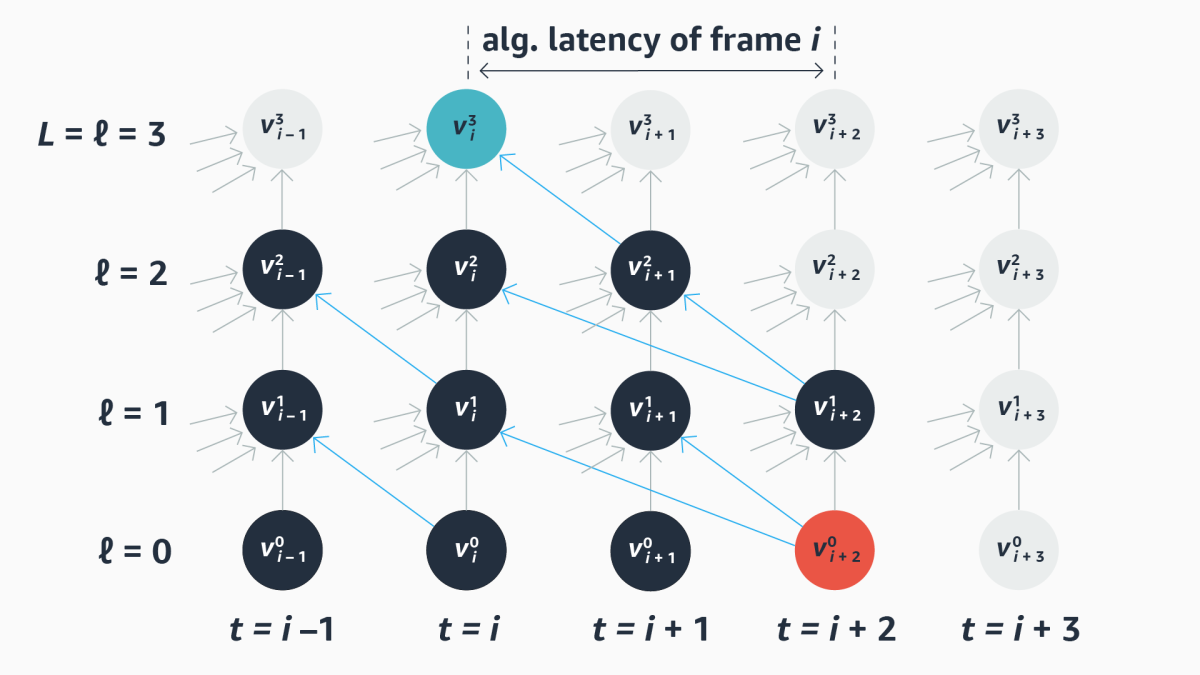
We represent the computations executed by our model with a computational graph. From left to right, the graph depicts successive time steps in the processing of input frames; from bottom to top, it depicts successive layers of the ASR network, from input to output. Edges in the graph depict causal relationships between nodes at past time steps and nodes at the current time step, and they also depict dependency relationships between nodes at future time steps and the current output.
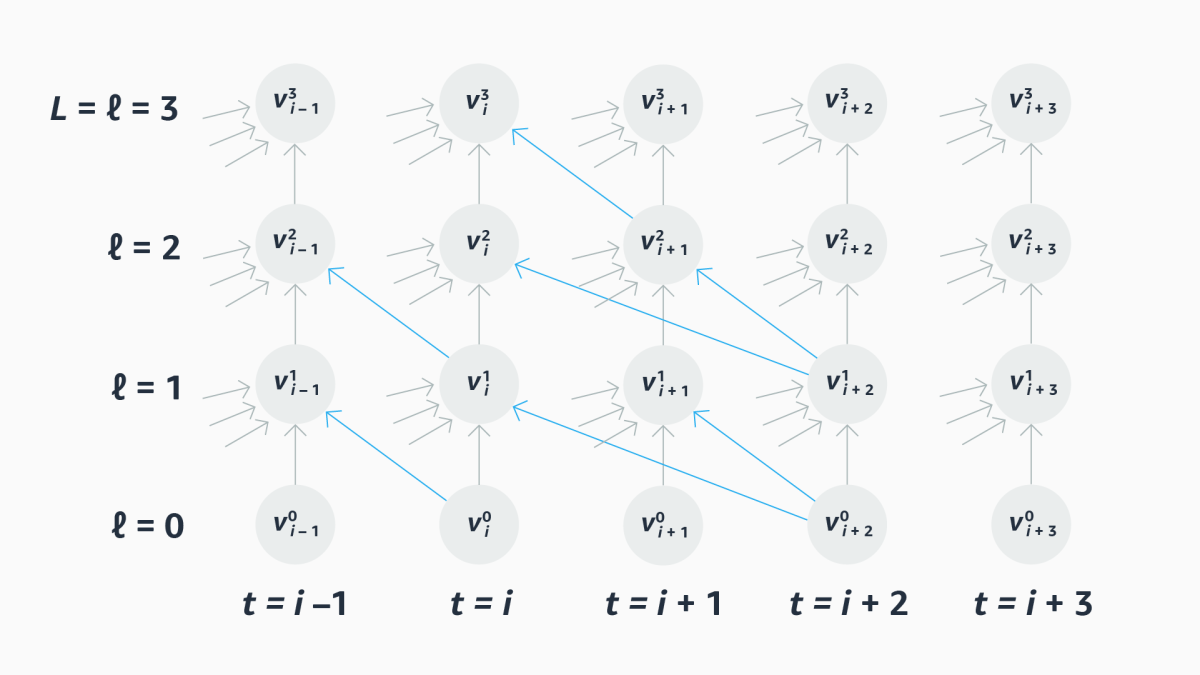
We represent each layer in the graph, in turn, with an adjacency matrix, which maps all the layer’s nodes against those from the prior layer; the value in any cell of the matrix indicates the row node’s dependency on the column node.
The matrix of a purely causal model is divided by a diagonal from top left to bottom right; all the values to the right of the diagonal are zero, because there are no dependencies between future time steps and the current time step. An entirely noncausal model, by contrast, has a full matrix. A standard lookahead model has a diagonal that’s offset by as many frames as it looks ahead.
Our goal is to train a scheduler that generates adjacency matrices on the fly, with differing degrees of lookahead for different rows of the matrices. We call these matrices masks, because they mask out parts of the adjacency matrix.
Annealing
Ultimately, we want the values of the masks to be binary: either we look ahead to a future frame or we don’t. But the loss function we use during training must be differentiable, so we can use the standard gradient descent algorithm to update the model weights. Consequently, during training, we allow fractional values in the adjacency matrices.
In a process known as annealing, over the course of successive training epochs, we force the values of the adjacency matrix to diverge more and more, toward either 1 or 0. At inference time, the values output by the model will still be fractional, but they will be close enough to 1 or 0 that we can produce the adjacency matrix by simple rounding.
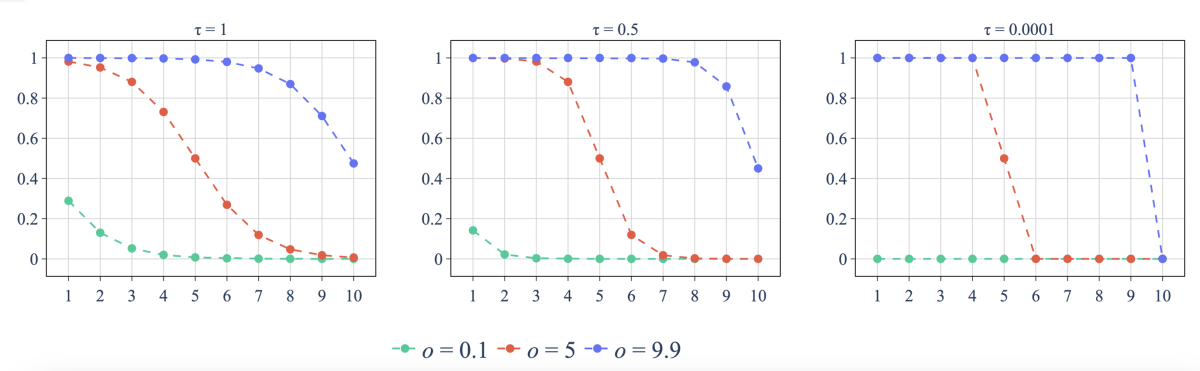
Latency
A lookahead ASR model needs to balance accuracy and latency, and with our architecture, we strike that balance through the choice of loss function during training.
A naïve approach would be simply to have two terms in the loss function, one that penalizes error and one that penalizes total lookahead within the masks as a proxy for latency. But we take a more sophisticated approach.
During training, for every computational graph generated by our model, we compute the algorithmic latency for each output. Recall that, during training, the values in the graph can be fractional; we define algorithmic latency as the number of time steps between the current output node and the future input node whose dependency path to the current node has the highest weight.
This allows us to compute the average algorithmic latency for all the examples in our training set and, consequently, to regularize the latency measure we use during training. That is, the latency penalty is not absolute but relative to the average lookahead necessary to ensure model accuracy.
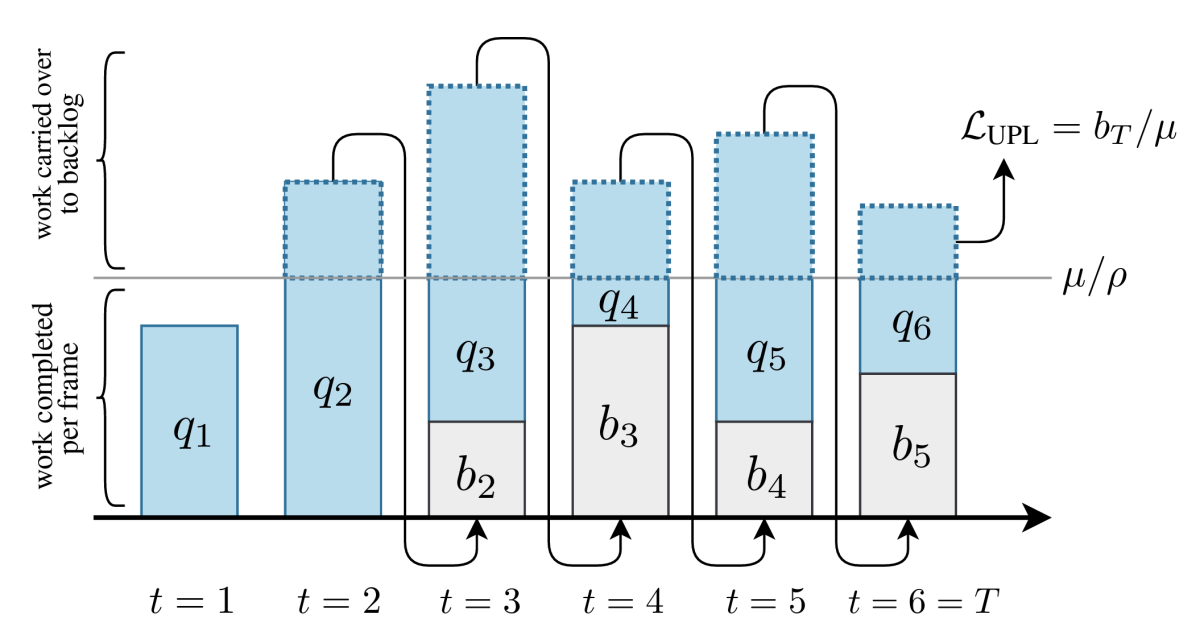
In a separate set of experiments, we used a different notion of latency: computational latency, rather than algorithmic latency. There, the key was to calculate how much of its backlogged computations the model could get through in each time step; the unfinished computations after the final time step determined the user-perceived latency.
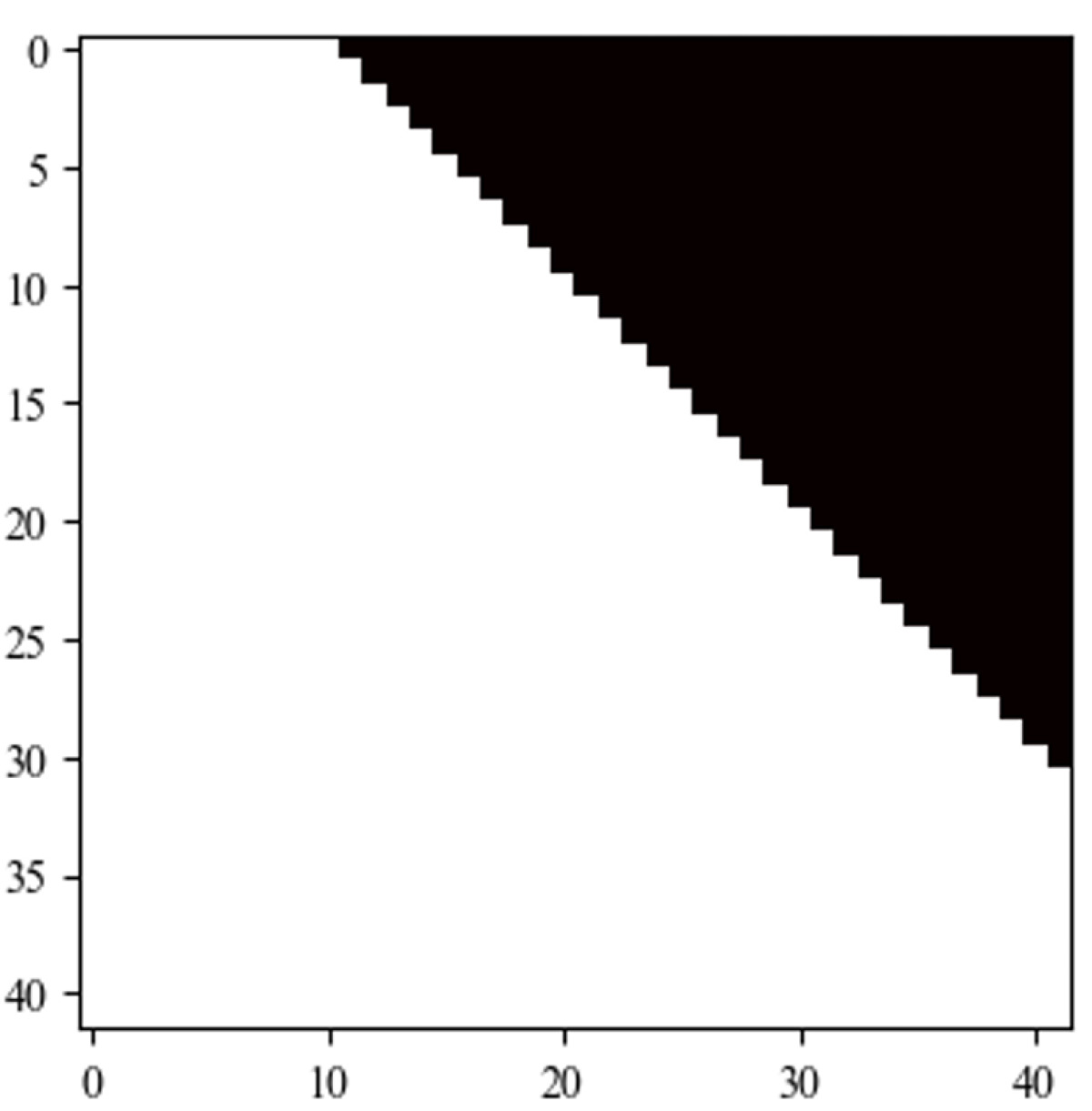
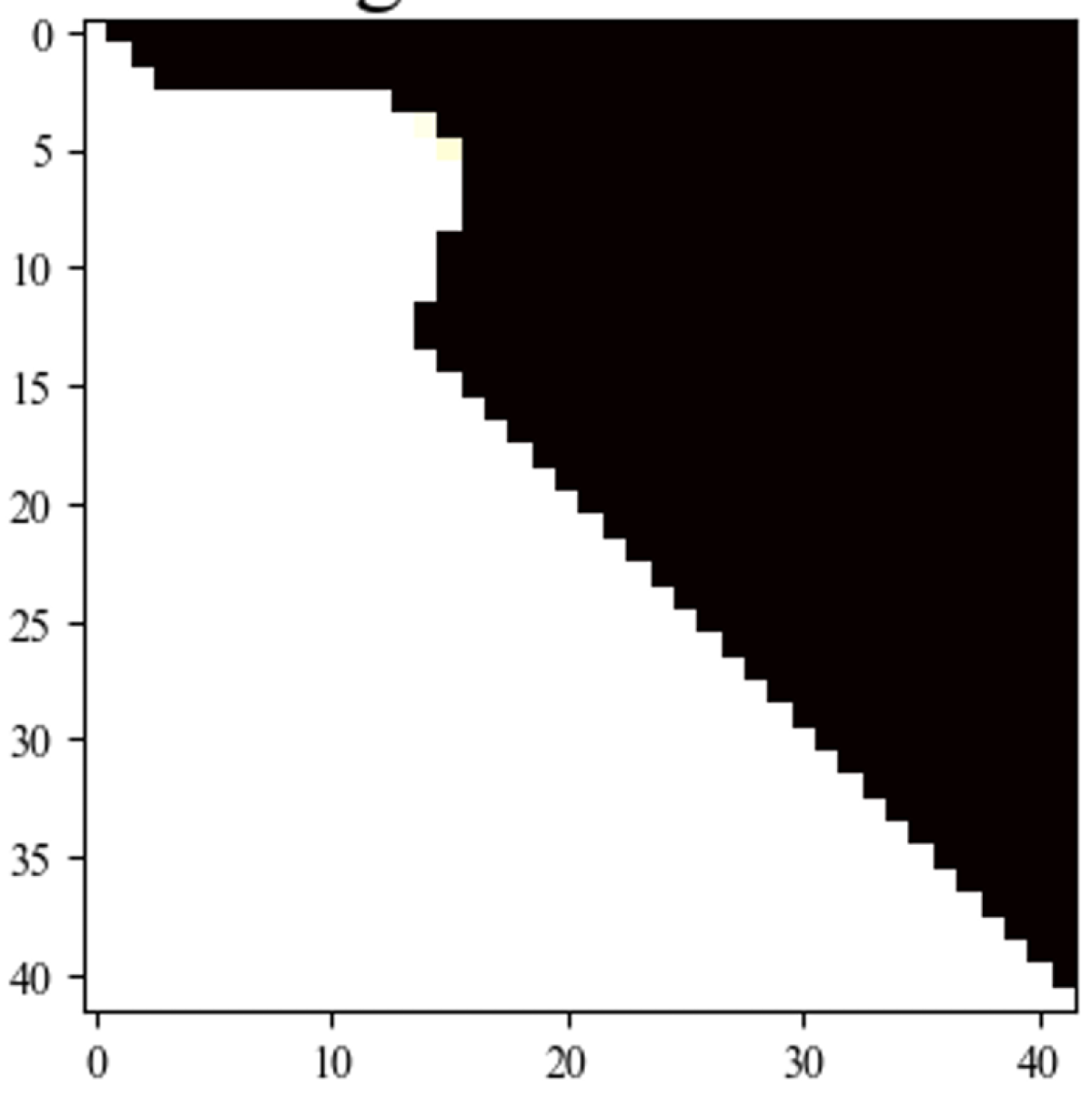
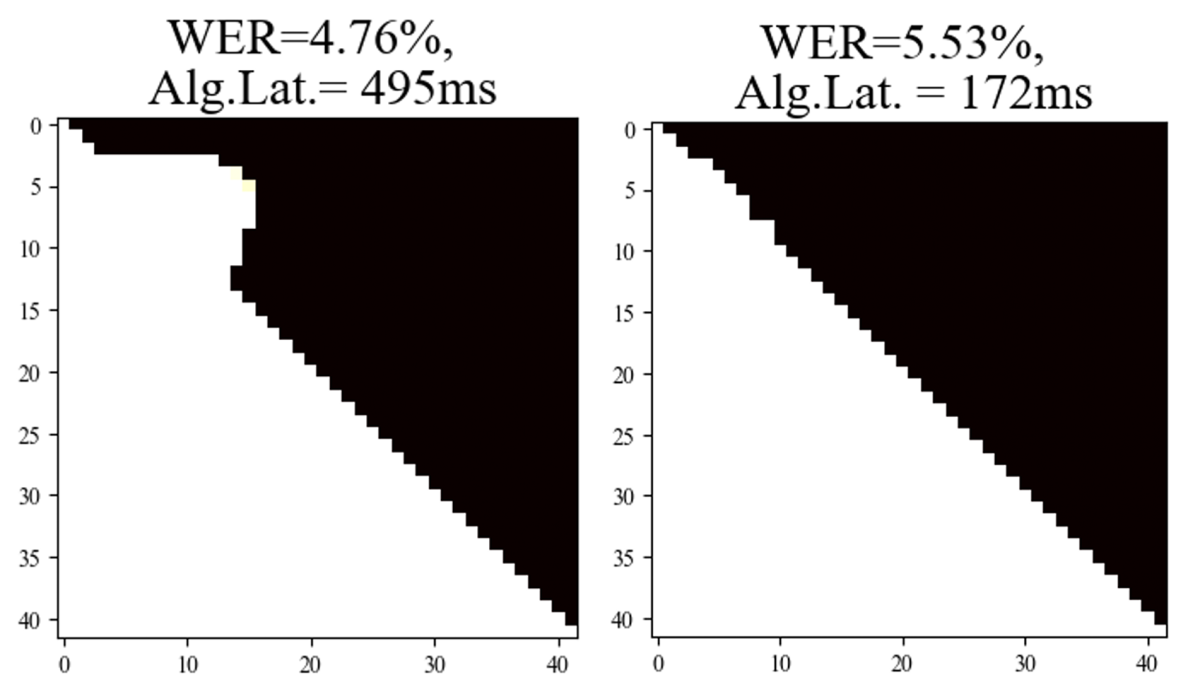
As with any multi-objective loss function, we can tune the relative contribution of each loss term. Below are masks generated by two versions of our model for the same input data. Both versions were trained using algorithmic latency, but in one case (right), the latency penalty was more severe than in the other. As can be seen, the result is a significant drop in latency, but at the cost of an increase in error rate.
We compared our model’s performance to four baselines: one was a causal model, with no lookahead; one was a layerwise model, which used the same lookahead for each frame; one was a chunked model, which executes a lookahead once, catches up with it, then executes another lookahead; and the last was a version of our dynamic-lookahead model, except using the standard latency penalty term. We also tested two versions of our model, one built with the Conformer architecture and one with the Transformer.
For the fixed-lookahead baselines, we considered three different lookahead intervals: two frames, five frames, and 10 frames. Across the board, our models were more accurate than all four baselines, while also achieving lower latencies.
Acknowledgments: Martin Radfar, Ariya Rastrow, Athanasios Mouchtaris