In a keynote address at this year’s ACM Conference on Recommender Systems (RecSys), which starts next week, Rajeev Rastogi, vice president of applied science in Amazon’s International Emerging Stores division, will discuss three problems his organization has faced in its work on recommendation algorithms: recommendations in directed graphs; training machine learning models when target labels change over time; and leveraging estimates of prediction uncertainty to improve models’ accuracy.
“The connections are that these are general techniques that cut across many different recommendation problems,” Rastogi explains. “And these are things that we actually use in practice. They make a difference in the real world.”
Directed graphs
The first problem involves directed graphs, or graphs whose edges describe relationships that run in only one direction.
“Directed graphs have applications in many different domains out there — from citation networks, where an edge U-V indicates paper U cites paper V, or in social networks, where an edge U-V would show that user U follows another user V, and in e-commerce, where an edge U-V indicates that customers bought product U before they bought product V,” Rastogi explains.
Although the problem of exploring directed graphs is general, the researchers in Rastogi’s organization focused on this last case: related-products recommendation, where the goal is to predict what other products might interest a customer who has just made a purchase.
“The interesting part here is that the related-products relationship is actually asymmetric,” Rastogi explains. “If you have, say, two nodes, a phone and a phone case, given a phone, you want to recommend a phone case. But if the customer has bought a phone case, you don't want to recommend a phone, because they most likely already have one.”
Like many graph-based applications, the Amazon team’s solution to the problem of asymmetric related-product recommendation involves graph neural networks (GNNs), in which each node of a graph is embedded in a representational space where geometric relationships between nodes carry information about their relationships in the network. The embedding process is iterative, with each iteration factoring in information about nodes at greater removes, until each node’s embedding carries information about its neighborhood.
“A single embedding space does not have the expressive power to model the asymmetric relationships between nodes in directed graphs,” Rastogi explains. “Something that we borrowed from past work is to represent each node with dual embeddings, and one of our novel contributions is really to learn these dual embeddings in a GNN setting that leverages the entire graph structure.”
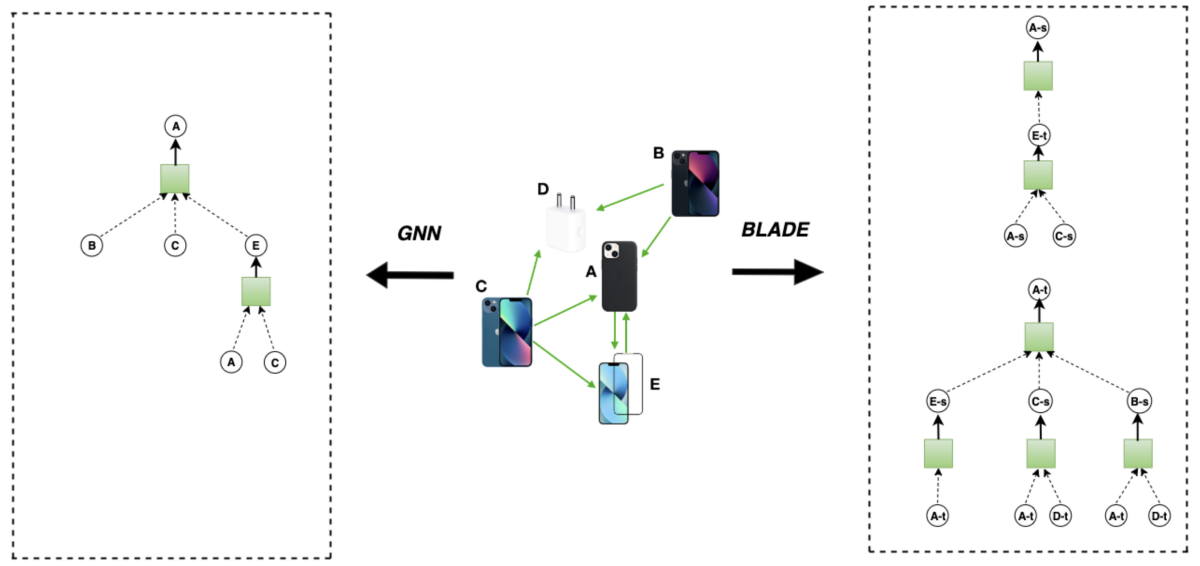
“Then we had additional techniques, like adaptive sampling,” Rastogi adds. “These vanilla GNNs sample fixed neighborhood sizes for every node. But we found that low-degree nodes” — that is, nodes with few connections to other nodes — “have suboptimal performance when you have fixed neighborhood sizes for every node, because low-degree nodes have sparse connectivity structures. And so less information gets transmitted when you're aggregating information from neighbors and so on.
“So we actually choose to sample larger neighborhoods for low-degree nodes and smaller neighborhoods for high-degree nodes. It's a little bit counterintuitive, but it gives us much better results.”
Delayed feedback
A typical machine learning (ML) model is trained on labeled data, and the model must learn to predict the labels — its training targets — from the data. The second problem Rastogi addresses in his talk is how best to train a model when you know that some of the target labels are going to change in the near future.
“This is, again, a very common problem across many different domains,” Rastogi says. “In recommendations, there can be a time lag of a few days between customers viewing a recommendation and purchasing the product.
“There's a trade-off here: If you use all the training data in real time, some of those more recent training examples may have target labels that are incorrect, because they are going to change over time. On the other hand, if you ignore all the training examples you got in the last five days, then you're missing out on recent data, and your model isn't going to be as good — especially in environments where models need to be retrained frequently.
“Here, what we've done is come up with an importance-sampling strategy that essentially weighs every training example with an importance weight. Let P(X,Y) be the true data distribution, and Q(X,Y) be the data distribution that you observe in the training set. Our importance-sampling strategy uses the ratio P(X,Y) divided by Q(X,Y) as the importance weight.
“Our key innovation centers on techniques to compute these importance weights in new scenarios. One is where we take into account preconversion signals. People tend to do something before they convert; they may add to cart, or they may click on the product to research it before completing the purchase. So we take into account those signals, and that helps us overcome data sparsity.
“But then it makes the computation of importance weights a little bit more complex. If it's very likely that the target label will actually change from 0 — a negative example — to 1 , then the importance weight would be much lower than if the likelihood of the example not changing was very low. Essentially, what you're trying to do is learn from the data the likelihood that the target label is going is change in the future and capture that in the importance weights.”
Prediction uncertainty
Finally, Rastogi says, the third technique he’ll discuss in his talk is the use of uncertainty estimates to improve the accuracy of model predictions.
“ML models typically will return point estimates,” Rastogi explains. “But usually you have a probability distribution. In some cases, you could know there's a 0.5 chance this customer is going buy the product. But in some cases, it could be anywhere between 0.2 and 0.8. What we found is, if you’re able to generate uncertainty estimates for model predictions, we can exploit them to improve model accuracy.
“We trained a binary classifier to predict ad click probability for an ads recommendation application. For every sample in the holdout set, we generated both the model score, which is the probability prediction, and also an uncertainty estimate, which is how certain I am about the predicted probability.
“If I looked at a lot of examples in the holdout set with a model score of 0.5, you would expect that about 50% of them resulted in clicks: that’s the empirical positivity rate. If it were 0.8, then the empirical positivity rate should be around 80%.
“But what we found is that as the variance of the model score increased, the empirical positivity rates went down. If I have a score of 0.8, I could say, well, it's between 0.79 and 0.81, which corresponds to a low variance. Or I could say, it's between 0.65 and 0.95, which indicates a high variance. We found that for the same model score, as the confidence intervals became larger, the empirical positivity rate started dropping.
“That has implications on selecting the decision boundary for binary classifiers. Traditionally, binary classifiers used a single threshold on model scores. But now, since the empirical positivity rate depends on both the model score and the uncertainty estimate, just selecting a single threshold value turns out to be suboptimal. If we select multiple thresholds, one per uncertainty level, we found that we can get much higher recall for a given precision.”
Members of Rastogi’s organization are currently writing a paper on their prediction uncertainty work — but the method is already in production.
“There are a lot of things that people publish papers about, and they're forgotten and never really used,” Rastogi says. “Coming from Amazon, we do science that actually makes a difference to customers and solves customer pain points. These are three examples of doing customer-obsessed science that actually makes a difference in the real world.”