
The total amount of data that is created, captured, copied, and consumed globally each year is accelerating rapidly and is forecast to reach 120 zettabytes in 2023, according to Statista. That’s up from nine zettabytes in 2013 (for reference, a zettabyte is the equivalent of roughly 500 billion movies.)
Organizations around the world are hoping to tap into the opportunity presented by this data deluge: to build a data foundation, use it to feed artificial-intelligence (AI) models, and derive insights from it. Research from Forrester shows that experienced data-driven businesses were 8.5 times more likely than beginners to experience 20% revenue growth in 2021. Yet according to the Harvard Business Review, only 26.5% of businesses successfully treat data as a strategic asset.
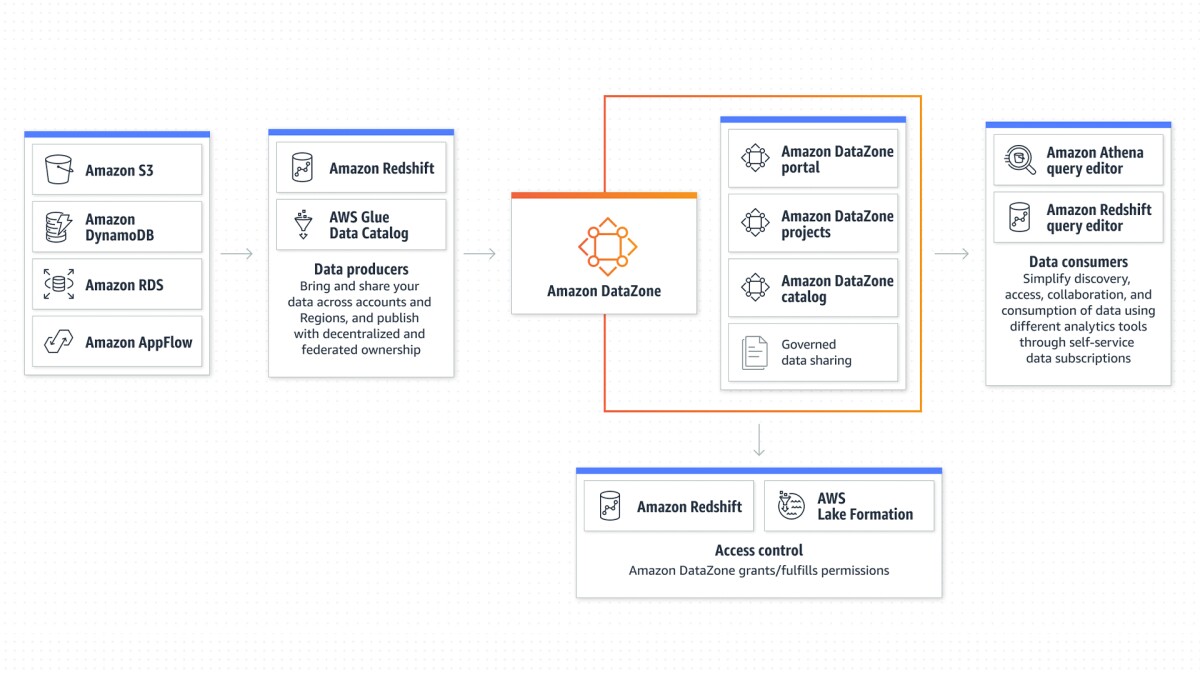
To help customers meet the data management challenge, Amazon Web Services (AWS) introduced Amazon DataZone, which makes it faster and easier to catalog, discover, share, and govern data stored across AWS, on the customers' premises, or by third-party sources. AWS recently announced that the service is now generally available.
“Our customers want a simple way to get all of their data together, no matter where it is stored and in what format, and they want their analysts, data scientists, and engineers to get value out of it as fast as possible,” said Shikha Verma, senior manager and head of product for Amazon DataZone at AWS. “That’s the problem we are solving.”
The manifold challenges of data management
Verma and her AWS colleagues recognized a need for a new data management solution about three years ago. At the time, multiple teams within AWS were encountering similar versions of the same data management problem: how to discover, share, and govern data located in siloed databases. They also knew this problem was not unique to AWS.
“If you can’t discover the right data, things are dead in the water,” said Florian Saupe, a principal technical product manager at AWS who is working on improving Amazon DataZone via machine learning capabilities.
Another persistent challenge was the fact that data — and the metadata that describes it — is stored in technical formats and optimized for processing by powerful analytics tools like Amazon Redshift. Those twin realities make it hard for nontechnical users to discover, organize, and glean valuable insights from their data.
In addition, noted Huzefa Rangwala, a senior manager of applied science who works on DataZone, customers can find themselves spending hours sifting through hard-to-parse data, running the risk of overlooking crucial slices of that data.
“This is where Amazon DataZone comes in,” Rangwala said. The service connects siloed data assets and enables customers to quickly discover datasets within their organizations.
Automated metadata generation
A key feature of Amazon DataZone is automated metadata generation. Typically, customers add metadata manually in an effort to make their data discoverable and understandable.
“That’s tedious, error-prone work that does not scale,” said Saupe. “This metadata is also often cryptic and uses a lot of jargon and abbreviations.”
For example, when data is added to a database, some of the associated metadata may come in the form of abbreviations such as “C_Name” — rather than “Customer Name” — as the header for a table column.
“We used machine learning techniques to automatically generate understandable business names from these cryptic names in datasets to help users better understand their data,” said Jiani Zhang, an applied scientist at AWS.
To achieve this, she and her colleagues created a training dataset of abbreviated column names and the corresponding expanded labels and used it to fine-tune a large language model. When activated with a click in Amazon DataZone, the model automatically generates column name expansions that nontechnical users can understand.
The addition of this automatically generated and easy-to-understand metadata makes datasets easier to search and makes specific data more discoverable for nontechnical users, noted Verma. That discoverability also mitigates the risk that data analysis may be undermined by incomplete and hard-to-understand data.
Enabling enterprise-wide collaboration
During the preview of Amazon DataZone, Verma and her colleagues heard feedback that while some customers wanted a tool for a single business unit or line of business, others sought an enterprise-wide solution that enabled better governance of data across the board.
“Between then and now, we enabled both types of adoption cycles,” Verma said. “So say a sales team wants to get started with Amazon DataZone: they can set up a domain, create their own projects, start sharing their data. Then, a month later, the marketing folks look at what sales has done, and now they want to get started. They can get started on their own timeline.”
Another challenge the team faced was creating an interface that bridges the variety of places customers store data and the tools they use to organize and analyze it. The goal was to empower different people to utilize the tools they prefer, even while working together on the same data. To move toward that goal, the team is introducing a new concept: a data project that brings people, tools, and data together under a single umbrella that coordinates security and access policies.
“You can give authorization to use that particular dataset to a project, and then all the people associated with that project carry the same authorization and context as they go into the tool of their choice,” Verma said.
“This construct of the data project is one of the biggest simplifiers that we are introducing with Amazon DataZone," Verma added. "It will help customers not just with bringing the right set of tools together in the AWS landscape but also with partner systems and solutions. We will offer a full set of APIs for our partners to be able to integrate with the same constructs that we are offering for AWS."
“Simplification across a heterogeneous landscape"
While these are early days for Amazon DataZone, feedback from customers during preview has already shown that it’s having the desired effect of serving as the single place for data scientists, analysts, engineers, and other people who interact with data to go to find the information they need, noted Verma.
And, she added, while AWS has always been aware that data management is a heterogeneous landscape, the Amazon DataZone team has seen the benefit of making Amazon DataZone work with the tools and data sources customers know and trust.
“That simplification across the heterogeneous landscape is a huge benefit for the customer,” Verma said.
Going forward, the team will continue to expand Amazon DataZone’s integration with third-party data tools and sources. In addition, the team will continue to focus on introducing additional simplification via automation that will make data more easily discoverable, make it more understandable, and facilitate the extraction of insights.
“We really want to lower the barrier for entry into data analysis for nontechnical data users and data people,” Verma said. “We will make it easier and easier for them to catalog data, easier for them to find data, and then easier for them to use data.”



